Le 21 mai 2018, à 12h26 (heure de Paris), nous avons passé le cap des 100 000 caractères labellisés sur la plate-forme Vision du Calfa.fr. Cette prouesse, unique dans le monde de l'arménologie, a été possible grâce à la cinquantaine de visionnautes (ndlr : utilisateurs de Vision), qui participent et nous aident dans nos recherches pour la préservation du patrimoine manuscrit arménien. Au nom de toute l'équipe du Calfa, je tiens à leur exprimer ma sincère reconnaissance.
Ce cap constitue un excellent prétexte pour réaliser un premier point sur cette base de données de caractères, et réfléchir aux 100 000 prochains labels.
Depuis l'été 2017, plus de 180 folios de manuscrits ont donc été labellisés. Ces folios proviennent de deux fonds :
du Walters Art Museum de Baltimore (États-Unis d'Amérique), qui possède onze manuscrits arméniens du Xe au XVIIIe siècle et qui met à disposition du public des numérisations en haute définition sur son site : cliquer pour accéder. Les manuscrits arméniens sont archivés sous les cotes W537 à W547. Excepté les manuscrits W545 et W547 qui sont des hymnaires, il s'agit d'évangiles ;
du Musée Arménien de France qui, avec le concours de l'Institut de Recherche en Histoire des Textes (IRHT-CNRS), a numérisé l'ensemble de son fonds qui contient dix-neuf manuscrits. Les numérisations sont disponibles dans la bibliothèque virtuelle des manuscrits médiévaux de l'IRHT-CNRS, sous les cotes MAF50 à MAF68. Grâce au partenariat signé par le Calfa avec ces institutions en mars 2018, 250 folios de ces manuscrits sont disponibles sur Vision Calfa et sont prêts à être labellisés. Ils datent du XIVe au XIXe siècle. Il s'agit de textes très variés : des hymnaires, un manuel de chants, le Livre de lamentation de Grégoire de Narek, le Livre de prophéties de Margar Khotchents, la Chronique de Mathieu d'Edesse, un évangile, des psaumes, des sermons, des synaxaires et un bréviaire.
Les notices de ces manuscrits ne mentionnent en général qu'un seul copiste, ce qui, pour le Calfa, en réduit un peu l'intérêt car un copiste fait l'effort d'être régulier dans son écriture et que nous sommes au contraire à la recherche d'une très grande variété dans la forme des lettres. Toutefois, en étudiant attentivement chaque folio et en tenant compte des pages de garde (qui sont souvent des folios de manuscrits plus anciens réutilisés) et des colophons, nous avons pu identifier plus d'une cinquantaine de mains et/ou de plumes. En outre, suivant le type de texte ou sa mise en page (Table des canons d'Eusèbe, rubriques, légendes d'illustrations, etc.), la forme des lettres s'est avérée très variable. C'est la raison pour laquelle nous avons pu mettre en ligne plusieurs folios d'un même manuscrit et que la base de données présente aujourd'hui une si grande et si riche variété.
À quoi ça sert ?
En nous aidant à construire cette base de données de caractères, vous participez à un ambitieux projet pour le développement d'un moteur de reconnaissance de caractères arméniens. Les recherches que nous menons font appel aux dernières avancées en intelligence artificielle, et notamment en apprentissage profond (Deep Learning). Il s'agit d'entraîner un réseau de neurones numériques avec un grand nombre de caractères - réseau de neurones dont le fonctionnement est inspiré du cerveau humain. De même qu'un enfant a besoin d'être confronté plusieurs fois à un même objet, sous toutes ses formes, pour le définir et l'identifier, nous soumettons à notre système autant de fois que nécessaire les lettres arméniennes pour qu'il arrive à en généraliser les formes et qu'il puisse les identifier quelle que soit la main qui écrit ou la disposition du texte.
Les résultats que nous obtenons sont extrêmement encourageants et vous seront bientôt présentés directement sur la plate-forme.
Et maintenant ?
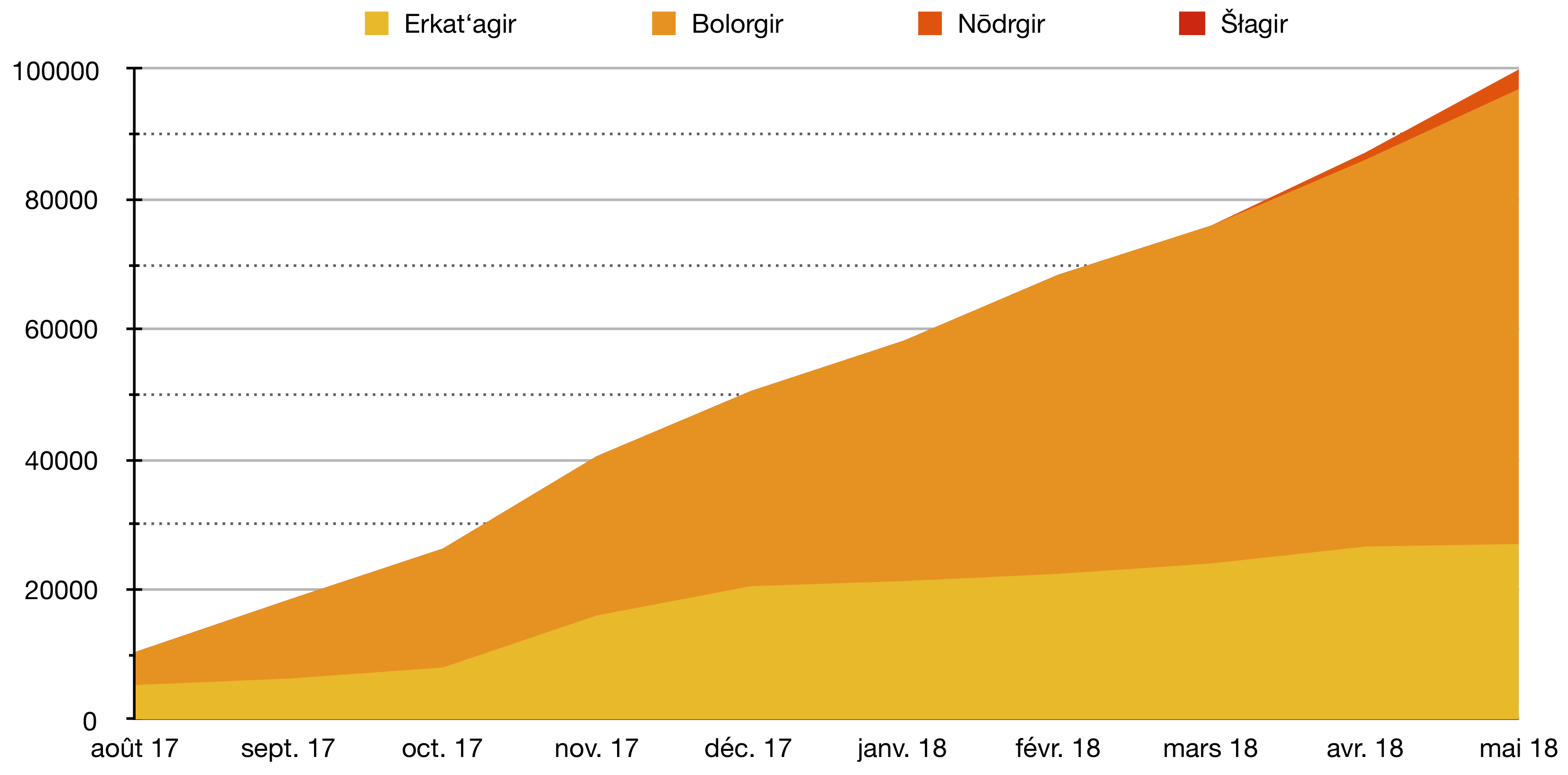
Répartition des labels par type d'écriture d'août 2017 à mai 2018
Sur les 100 000 caractères de la base de données, 27% sont en erkat‘agir, 70% sont en bolorgir et 3% sont en nōdrgir1. Si la base de données de caractères manuscrits arméniens de Vision Calfa présente déjà en elle-même un intérêt certain pour l'étude des lettres arméniennes, il est nécessaire d'en augmenter le contenu pour améliorer nos systèmes.
Durant les prochaines semaines, nous allons mettre en ligne la suite des folios de manuscrits du Musée Arménien de France, en augmentant notamment la part de nōdrgir et en ajoutant également des manuscrits en šłagir.
Une nouvelle interface de Vision Calfa devrait bientôt voir le jour, avec de nouvelles fonctionnalités, afin de rendre la labellisation plus ludique et encore plus rapide, et d'accélérer la préservation du patrimoine manuscrit arménien. Ne manquez donc pas les prochaines informations. Rejoignez la communauté, l'inscription est rapide et gratuite.
Merci !
1 Nous présenterons plus en détail ultérieurement chacun de ces types d'écriture.